Junior Data Analyst? בטוח נתקלת בסיטואציה הבאה: כתבת קווארי ארוך ומורכב עם המון חישובים ומניפולציות על strings, אולי עשית איזה בדיקה קטנה על דאטה מצומצם. את מתרגשת לראות שהכל עובד ועכשיו מנסה לשלוף על כל טווח הנתונים שאת צריכה. את לוחצת על כפתור הRun עם התרגשות קלה. ומחכה… ומחכה… ומחכה…
בתור משתמשי SQL, נחסכת מאיתנו המחשבה על איך הDBMS (מערכת ניהול בסיס הנתונים) בוחר לשלוף את הנתונים. כדי לשפר יעילות של שאילתא, צריך להכיר קצת (נשבע שקצת) איך עובד Relational Database. בפוסט זה אתרכז בנושא אחד מיני רבים שיעזור לכן לשפר את יעילות השאילתות שלכן – Partition.
Partition היא מילה שנזרקת הרבה כשמנסים לעשות אופטימיזציה של קווארי. מה זה אומר? איך משתמשים בזה ואיפה זה פוגש את האנליסט?
איך שולפים נתונים *בלי* להתחשב ביעילות?
נניח ונתונה הטבלה הבאה:
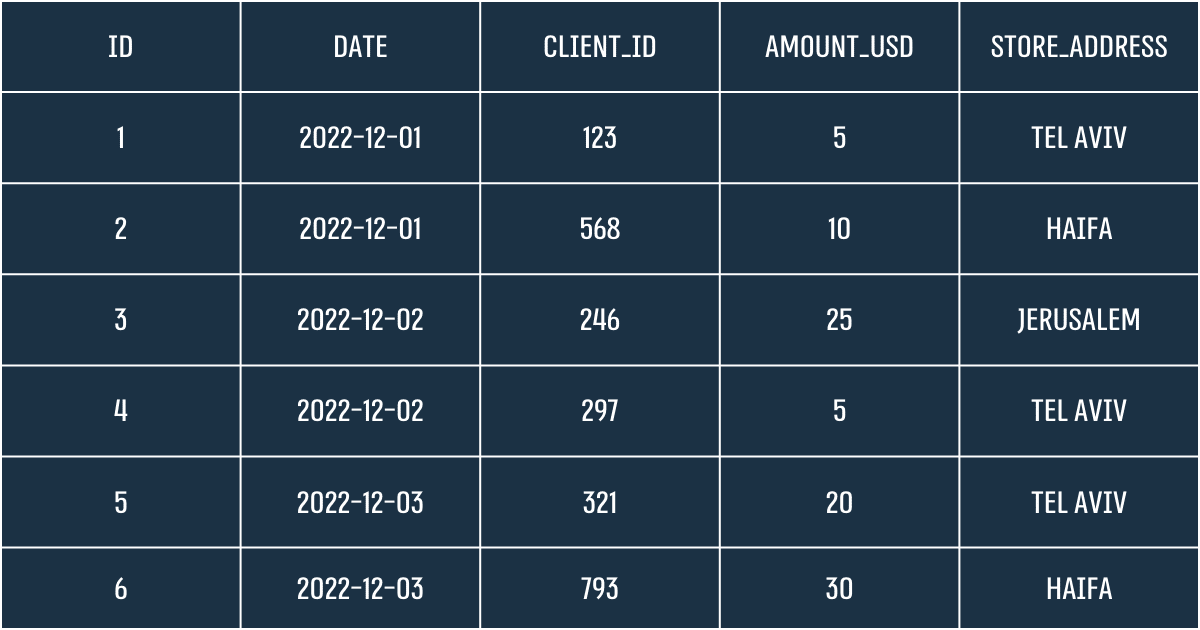
אם ארצה לשלוף ממנה רק עסקאות שקרו ביום מסויים, ארצה לכתוב קווארי כזה:
SELECT *
FROM transactions
WHERE DATE = '2022-12-02'
הדרך הפשוטה (ולא יעילה) של הDBMS לחפש את הערך אותו אני מנסה למצוא, תהיה לבדוק בכל שורה בעמודת 'DATE' האם התאריך = '2022-12-02'. בהנחה ומדובר בטבלה קטנה של כמה אלפי או עשרות אלפי שורות, זה לא ידרוש המון כוח חישוב. כשמדברים על טבלה של מיליוני שורות או עשרות מיליוני שורות, מדובר בפעולה שעלולה לקחת קצת זמן. בטח אם מדובר בחישוב אחד מיני רבים.
אז איך אפשר לייעל את השליפה? דרך אחת (מיני כמה) יכולה להיות דרך שימוש בPartition.
מה זה Partition ואיך זה מסייע ליעילות השליפה?
Partition היא חלוקה של הנתונים בטבלה למקטעים על בסיס לוגי במטרה לסייע ביעילות השליפה. כך הDBMS לא ידרש לעבור על כל השורות בטבלה, אלא רק על החלקים הרלוונטיים לשליפה הספציפית אותה אתם מנסים לבצע.
Partition יוגדר על ידי יוצר הטבלה. בארגונים רבים מדובר במפתח או הData engineer. לעיתים מדובר גם בדאטה אנליסט. ישנן מערכות בסיסי נתונים שקובעות Partition ברירת מחדל של עמודות מסויימות בעת יצירה של טבלאות על בסיס קריטריונים מסויימים.
איך מחליטים מה הוא אותו בסיס לוגי ליצירת Partition? הדבר תלוי בעיקר בדרך בה תתושאל הטבלה על ידי אנליסטים ו/או אפליקציות שניגשות אליה. אם אנחנו מעריכים ששליפות מהטבלה נעשות בדרך כלל רק בתאריכים מסוימים, קל ליצור Partition על בסיס תאריך. אם נראה ששליפות ממשתמשים מסוימים נעשות רק על על עמודת Region של אותם משתמשים, אולי יהיה נכון לחלק את הטבלה על בסיס אותה עמודה. אמחיש עם דוגמאות ספציפיות בהמשך.
סוגי Partition
Horizontal Partition – פרטישן מאוזן
תהליך של יצירת מספר טבלאות עם אותו מבנה וחלוקה של שורות הטבלה בין הטבלאות על בסיס לוגי.
סוגי Horizontal Partition נפוצים:
- זמן – במידה והטבלה מכילה עמודה מסויימת שמייצגת זמן, יתכן ונרצה ליצור partition לפי יום, חודש או שנה. זהו partition מאוד נפוץ מכיוון שפעמים רבות קווארי יתבצע על פרק זמן מסויים.
- אזור – בטבלאות המכילות אזורים עסקיים, פעמים רבות ה partition יתבצע על אזורים נפרדים מכיוון שמשמתמשים בטבלה יחפשו מידע שרלוונטי לאזור הספציפי שלהם.
- מידע עכשווי לעומת מידע היסטורי – יתכן ודאטה היסטורי יחולק אחרת מדאטה עם רלוונטיות עכשווית. נניח וקיימת לנו עמודת orders המכילה הזמנות של מוצרים על ידי לקוחות. יתכן ונכון לייצר partition נפרד על הזמנות פתוחות לעומת הזמנות שכבר נסגרו.
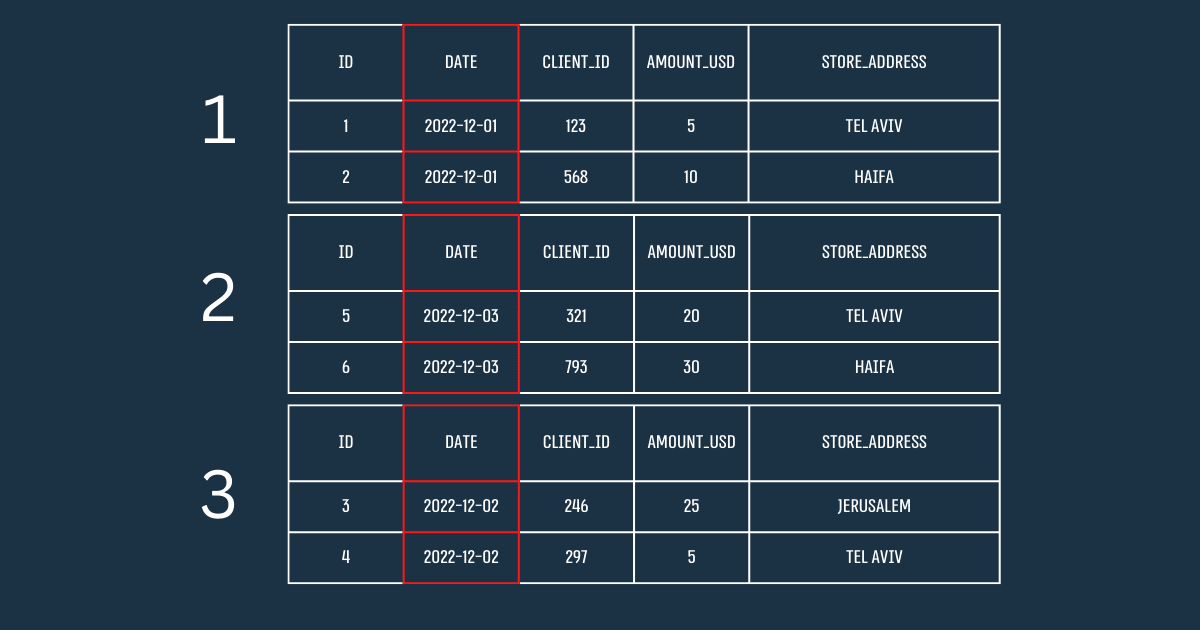
בדוגמא הבאה, ניתן לראות חלוקה של טבלה על בסיס זמן. עמודת Date משמשת לחלוקת הטבלה המקורית ל-3 טבלאות חדשות:
Vertical partition – פרטישן מאונך
יצירת מספר טבלאות עם אותו מספר שורות אך עם עמודות שונות. מתי ניצור פרטישן מאונך? אם שליפות מהטבלה לא משתמשות בעמודה מסויימת באופן תכוף, יתכן ונרצה להפריד אותה מהטבלה בעזרת Partition. בדוגמא הבאה, נראה כי חילקנו את הטבלה המקורית לשתי טבלאות שונות, אחת המכילה את כתובת החנות בו נקנה המוצר (STORE_ADDRESS) והשנייה לא. עמודת הID תאפשר שליפה של כתובת החנות במידה והיא תידרש להופיע כחלק מהטבלה המקורית.

איך משתמשים בPartition בקווארי?
לפני כל הרצה, הDBMS שלכם בונה מאחורי הקלעים Query Plan. התוכנית מיועדת לעשות אופטימיזציה לזמן שליפת הנתונים ממסד הנתונים. אחת הדרכים הקלות לסייע לQuery plan להיות יותר אופטימלית תהיה על ידי הכנסת ערכים מעמודות שהן Partitioned לפילטור בסעיף הWHERE של הקווארי. לדוגמא, אם טבלה מסויימת Partitioned על בסיס עמודת Date ואנחנו נבצע קווארי כזה:
SELECT *
FROM transactions
WHERE DATE = '2022-12-01'
הקווארי ירוץ הרבה יותר מהר מאם נכתוב קווארי שמפלטר על עמודה שאינה Partitioned. לדוגמא קווארי כזה:
SELECT *
FROM transactions
WHERE CLIENT_ID IN ('123','568')
זאת אפילו שהתוצאות שיופיעו כתוצאה מהשליפות יהיו זהות לחלוטין.
איך יודעים איך טבלה מסויימת Partitioned?
התשובה היא שכדי לראות Partition של טבלה מסויימת צריך בדרך כלל להריץ קווארי שיציג את טבלת Partitions שנמצאת בסכמת System או בסכמה אחרת שמכילה מטא-דאטה על הטבלאות בדאטה בייס של החברה שלכם. כן, זה לא משהו שאנליסטים מתעסקים איתו בדרך כלל. לא, זה לא כזה מסובך.
מכיוון שיש כל כך הרבה DBMS שונים (אורקל, MySQL, SQL Server ועוד ועוד), קצרה היריעה מלהסביר איך עושים את זה בכל DBMS. אני ממליץ לחפש בגוגל את התשובה לDBMS הרלוונטי לכם.
אפשרות אחרת להבין על בסיס מה טבלה היא Partitioned תהיה לשאול את המפתחים, צוות הData Engineering או הDBA.
סיכום
Partitioning היא דרך אחת מתוך מספר דרכים נפוצות להגברת יעילות שליפות מתוך מסד נתונים. יעילות ריצה היא דבר שיכול לתסכל אנליסטית מתחילה (או ותיקה!), לכן חשוב מאוד להבין מה זה אומר ואיך אפשר להשתמש במבנה של הדאטה בייס לטובתכן.
אשמח לכל שאלה, הבהרה או ביקורת. כתבו לי בתגובות או בעמוד!
